Ahrefs’ Crawler and Index
How Does Ahrefs Crawl and Index the Web
Before learning how to use each tool, it’s worth knowing where we get our data from.
At Ahrefs, we crawl the web much like search engines do: using crawlers.
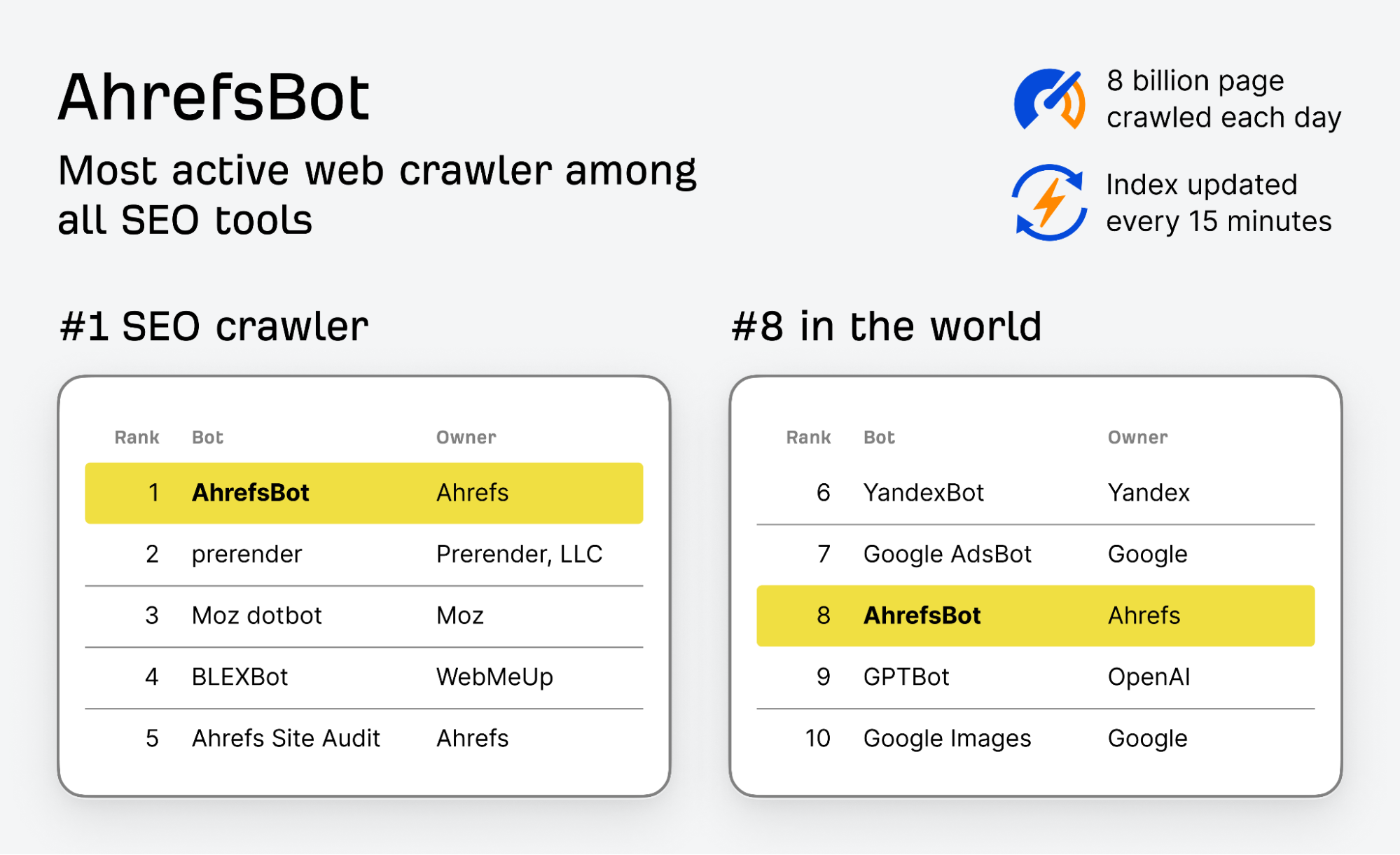
Our crawler is called AhrefsBot. It’s the #1 most active SEO crawler (and 8th most active crawler after Google’s and Bing's), visiting over 8 billion web pages every 24 hours and updating its index every 15–30 minutes.
Here’s how it works:
- Our crawler starts from a big list of known URLs.
- These URLs are then sent to the Scheduler, which decides when a URL should be crawled.
- When a URL is ready to be analyzed, AhrefsBot will send the URL to the Crawler and download its contents; all while strictly respecting the allow/disallow rules set in the robots.txt file.
- The crawler will deliver the raw data to the Parser, which extracts links on that page, the title, and other relevant metadata.
- The extracted data is then sent to the Indexer.
- It’s then added to the Link Index and made available in various reports in Ahrefs.
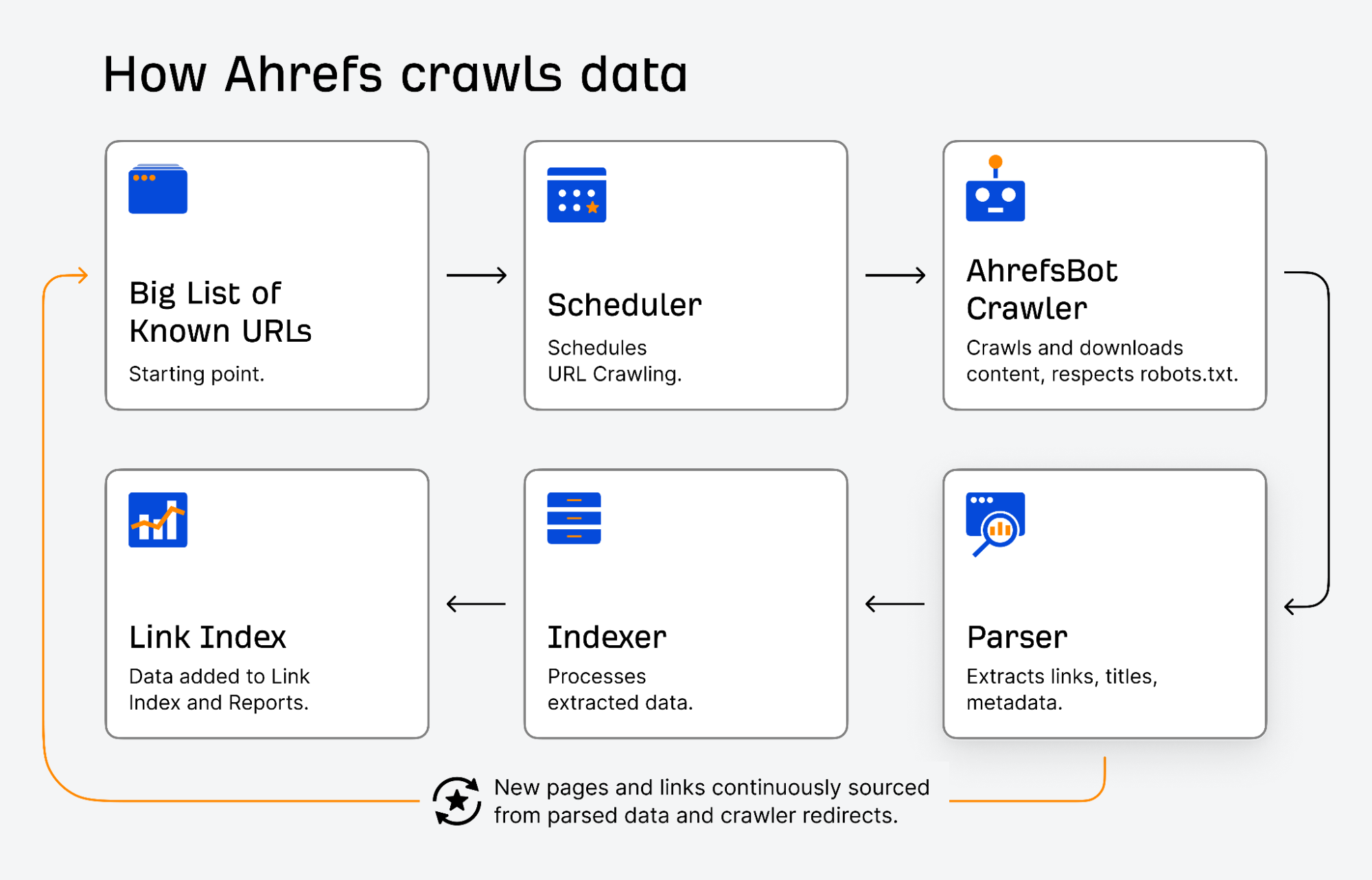
This is a linear and simplified explanation of how our crawler works. In order to continuously discover new pages and increase the size of our backlink index, we feed our list of URLs by surfacing new links from:
- Parsed data
- Redirects found via the Crawler
NOTE
Currently, we show live link data and links that were deleted in the last 60 days.